
Database Replication: Understanding Master and Slave Architecture
from zero to millions of users


Hi there it’s George here again with another System design Newsletter
Most often in large-scale applications, where millions of users are interacting with systems in real-time, databases play a critical role. Ensuring these databases are fast, reliable, and scalable is essential for a good user experience. This is where database replication comes into the picture. In this post, we’ll dive into the concept of database replication and explore the Master-Slave architecture, along with it’s game-changer benefits for modern systems.
What is Database Replication?
Database replication is the process of copying data from one database server (the Master) to one or more secondary servers (the Slaves) to ensure data availability and redundancy. Think of it as maintaining synchronized copies of your database to handle different tasks more efficiently. Imagine you have only one database but your users base have increase to the point that you’re now handling millions of reads and writes having a single database server could post threat of down time and slow read so you decided to make copy of the current database to help with the workload.
In the diagram below we see that our system handle requests of around 150K assuming 100K are when users are reading data from the system and 50k are when users are writing data to the system. The below diagram has lot of design weakness but we will only focus on the ones that are in relation to our topic.
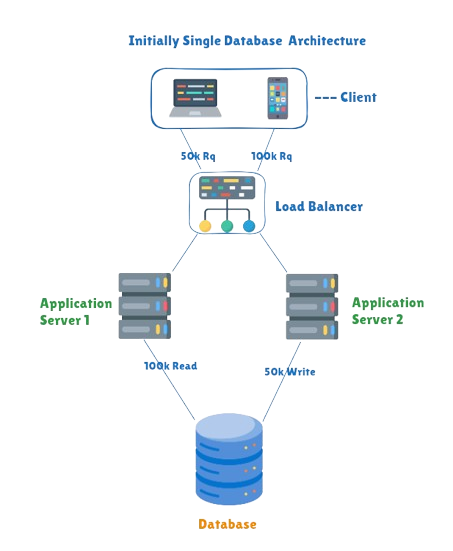
The first problem with this design is SPOF (Single point of failure) having a single database doing all the work our system stand the threat of experiencing the following
Slow data reading doing high throughput (Number of request the system can handle at a given time interval)
SPOF (Single point of failure) this means when the single database go down we could loose all our data or spend longer time trying to get out system up and running again thereby greatly hurting our user experiences.
To fix this we must applied data replication
Replication can be configured in different ways,
such as:
One-way replication: Data flows only from the Master to the Slave.
Bidirectional replication: Changes are synchronized between multiple servers.
In this design we see that only the master can update the slave so it possible that a slave database might not receive the latest change in cases the master suddenly go down.

In the below design we see that both the master and slave severs can update each other making it possible for the latest write or read data to be share across both the master and the slave databases.

This process ensures your data is safe and accessible, even under heavy workloads or during unexpected failures.
Let go deep into the Master-Slave Architecture
Master:
Acts as the primary server where all write operations (e.g., insert, update, delete) take place.
Responsible for propagating changes to the Slave servers.
Slave:
Receives a continuous stream of updates from the Master to stay synchronized.
Primarily used for read operations to offload work from the Master.
A Simple Example
Consider a blogging platform where users are constantly reading articles and leaving comments. Instead of overwhelming a single database server, the Master handles the comment-writing operations, while the Slaves handle reading requests for blog posts. This way, the system can efficiently manage thousands of users simultaneously.
Client (Writes) ---> Master ---> Slave (Replication)
Client (Reads) ---> Slave
Why Do We Even Need Database Replication?
Data Replication isn’t just some tech buzzwords design to make smart people look smarter; it solves real-world problems for growing systems. Here are the key benefits:
1. Improved Performance
By offloading read operations to Slave servers, the Master can focus on write-heavy tasks.
This improves overall system performance and reduces bottlenecks.
2. High Availability
If the Master fails, a Slave can be promoted to take over, ensuring minimal downtime.
Maintenance on one server won’t disrupt the system.
3. Data Backup
Slaves act as near real-time backups of the Master. This ensures data integrity in case of unexpected data loss.
4. Scalability
Need to handle more traffic? Just add more Slaves to distribute the load.
Especially useful for read-heavy applications like e-commerce platforms or content delivery networks.
5. Geo-Replication
Replicate data to servers in different geographical locations to reduce latency for users around the world.
For instance, a user in Africa can access a nearby Slave server instead of querying a Master located in the US.
Challenges of Master-Slave Replication
While replication is powerful, it’s not without its challenges:
1. Data Consistency
There can be a delay (replication lag) between when a change is made on the Master and when it’s reflected on the Slaves.
For time-sensitive applications, this lag might lead to inconsistencies.
2. Complexity
Setting up and managing replication requires expertise, especially for large systems with multiple Slaves.
3. Failover Management
When the Master goes down, promoting a Slave to Master isn’t always seamless. This process may require manual intervention or a robust automation strategy.
When Should You Use Master-Slave Replication?
Master-Slave replication isn’t a one-size-fits-all solution(Don’t say I didn’t warn you). It works best for:
Read-heavy applications: Systems with more read operations than write operations, such as blogs, social networks, or dashboards.
High availability needs: Applications where uptime is critical, and downtime must be minimized.
Backup and disaster recovery: Use cases where maintaining data redundancy is essential to mitigate risks.
Modern Alternatives and Improvements
The Master-Slave model is a strong foundation, but modern systems have evolved to tackle its limitations:
Multi-Master Replication
Multiple Masters can handle both reads and writes, providing even more scalability and redundancy.
Leaderless Replication
Databases like Cassandra use leaderless replication, where all nodes can act as peers. This avoids the single point of failure.
Cloud-Native Solutions
Services like Amazon Aurora or Google Spanner handle replication seamlessly, offering scalability and fault tolerance out of the box.
Conclusion
Database replication, especially the Master-Slave architecture, is one of the fundamental pillar of modern system design. It enables performance, scalability, and reliability—essentials for any growing application. While it has its challenges, the benefits far outweigh the costs in most scenarios.
Whether you’re designing a blog platform, a financial system, or a global e-commerce site, understanding and implementing database replication can elevate your system to the next level.
Have you worked with database replication before? What strategies did you use to handle its challenges? Let’s discuss in the comments below I like to learn from you!
References
"System Design Interview " - Alex Xu
"Master-Slave Replication in MySQL" - MySQL Documentation
"Distributed Systems for Practitioners" - Martin Kleppmann’s book Designing Data-Intensive Applications
"Geo-Replication and Performance Tuning" - AWS Documentation
"Modern Alternatives to Master-Slave" - Cassandra Documentation